The Introducton to IPFS
Location Addressing VS Content Addressing
Location addressing points us to the location where data is stored by a specific entity.
Two Drawbacks of Location Addressing:
Trustiness: it is difficult to verify what content resides at a particular URL and is dependent on central authorities
Efficiency: same content on different domains or with different filenames leads to a lot of redundancy
Content addressing provides a unique, content-derived identifier for the data, which we can use to retrieve the data from a variety of sources:
Content addressing with Cryptographic hashing liberates us from reliance on central authorities: Cryptographic algorithm will generate a completely different hash ,even if the change is small (e.g., a single pixel in an image)
Cryptographic hashes can be derived from the content of the data itself, meaning that anyone using the same algorithm on the same data will arrive at the same hash
Content Identifiers (CIDs)
A content identifier, or CID (Content Identifier), is a self-describing content-addressed identifier. It doesn’t indicate where content is stored, but it forms a kind of address based on the content itself.
A multihash is a self-describing hash which itself contains metadata that describes both its length and what cryptographic algorithm generated it.

- algo: identifier of the cryptographic algorithm used to generate the hash
- length: the actual length of the hash
- value: the actual hash value
After adding an encoding method (dag-pb) and a version prefix (Version 1), the final CID will become like this:
<cid-version> <multicodec> <multihash-algorithm> <multihash-length> <multihash-hash>

Merkle DAGs (Directed Acyclic Graphs)
IPFS uses CIDs to identify a node uniquely, and uses Merkle DAGs to express an edge from one node to another.

In a Merkle DAG, each node’s CID depends on every single one of its descendents; should any of those be different, their own labels would also be different. If, for example, the picture of a tabby cat were photoshopped in some way, then its respective node in the graph would receive a different CID. This means that we always have to build a DAG from the bottom up: parent nodes cannot be created until CIDs of their children can be determined.
In a Merkle DAG, the CID of each node depends on the CIDs of each of its children. As a result, the CID of a root node uniquely identifies not just that node, but the entire DAG of which it’s the root!
There are 3 features of Merkle DAGs using in IPFS:
Verifiability: an individual who retrieves data also verifies its CID
Distributability: 1) anybody who has a DAG is capable of acting as a provider for that DAG; 2) we can retrieve both the data and its children in parallel on a DAG
Deduplication: Merkle DAGs efficiently store data by encoding redundant sections as links
Distributed hash table (DHT)
To find which peers are hosting the content you want, IPFS uses a distributed hash table, or DHT. IPFS uses libp2p to provide the DHT, and to handle peers connecting and talking to each other.
Once you know where your content is located, you use the DHT again to find the current location of those peers (routing). So, in order to get to content, you use libp2p to query the DHT twice.
After discovering the content you want and its location(s), you need to connect to that content and get it (exchange). To request blocks from and send blocks to other peers, IPFS currently uses a module called Bitswap. Bitswap allows you to connect to the peer or peers that have the content you want, send them your wantlist (a list of all the blocks you’re interested in), and have them send you the blocks you requested. Once those blocks arrive, you can verify them by thier CIDs.
Libp2p
Libp2p is the networking stack of IPFS. The aim of libp2p is to solve the discoverability in p2p connection. However, libp2p is extracted away from IPFS, and each project focuses on its own objectives:
- IPFS is more focused on content addressing, i.e., finding, fetching and authenticating any piece of content in the web
- libp2p is more focused on process addressing, i.e., finding, connecting and authenticating any data transfer processes in the network
Libp2p implements this process addressing by Modularity, that is, a user can choose the specific pieces (e.g., Transport, NAT Traversal, Peer routing, etc) they need and compose their own configuration, tailored for their use cases.
Take the OSI Model (Open System Interconnection Model) as an example.
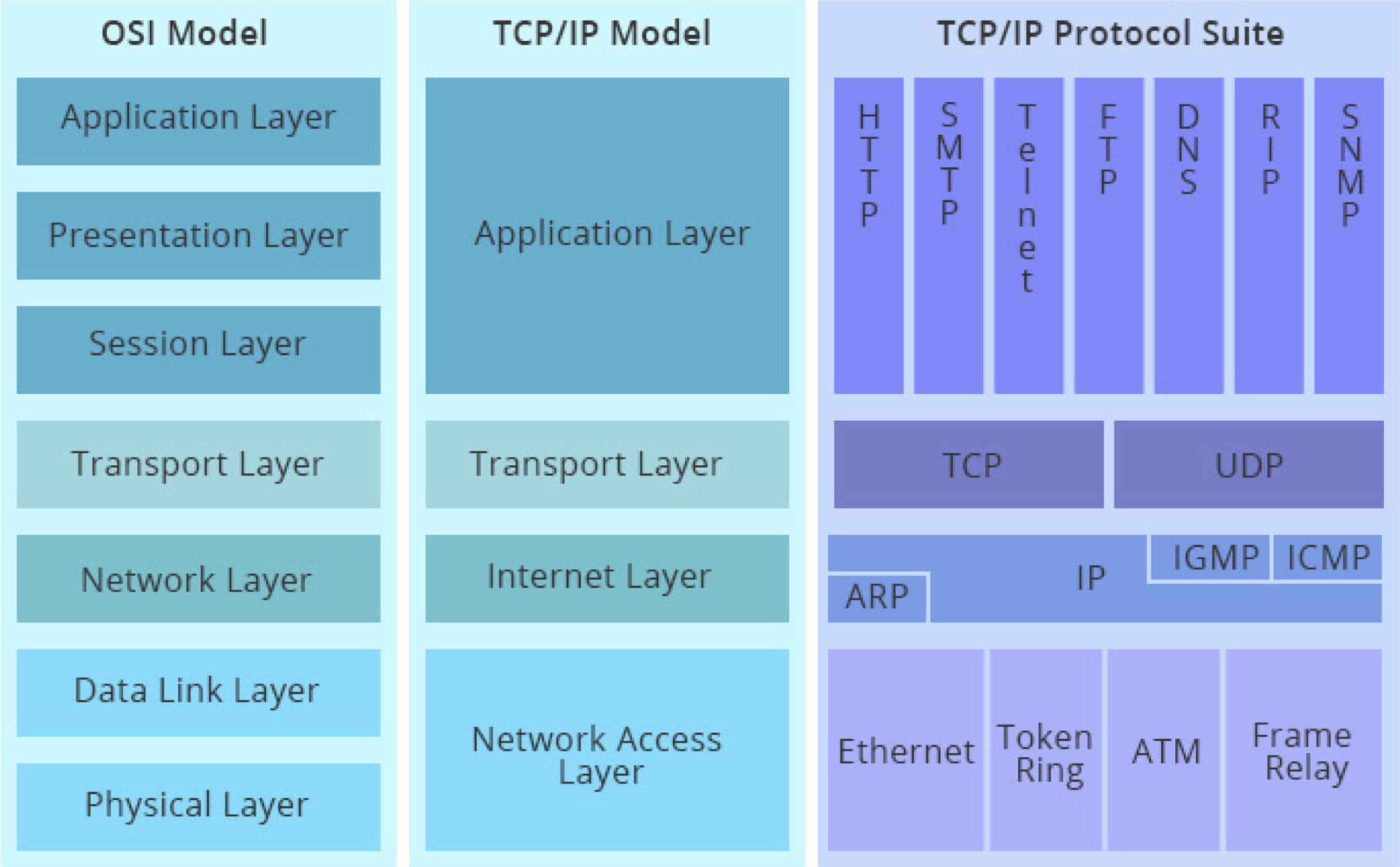
As we can see, the actual implementations in the current web do not follow the OSI Models exactly, and are much less tidy, e.g. the TCP/IP Protocol Suite shown above.
Instead, libp2p breaks the OSI Model apart and allows applications to mix and match freely without being restricted to rigid conceptual models.

Let’s take a look at what a NodeJs libp2p configuration (Shown as left figure above):
- the first part imports all the necessary libp2p modules that make up this network stack
- the second part is the libp2p node configuration where we add the different modules for each part of the network
However, for this code to run in the browser, which doesn’t support TCP transports, we only need to change the transport protocols and peerDiscovery protocols in our libp2p configuration
Filecoin
Filecoin adds an incentive layer to promote long term, verifiable storage on the decentralized web. Thanks to Filecoin’s blockchain, all participants in the network work together to verify each deal. These consensus mechanisms are how users in a distributed network come to agreement without the need for a central authority.
In the case of Filecoin, the storage miner is responsible for proving that they’re storing the correct data over time, and verifier duties are shared by all participants in the network.
Before a system file (e.g. puppy.gif) can be stored on the Filecoin network, it must first be transformed into a Filecoin Piece:
- in the first stage of this transformation, the system file is chunked up with UnixFS to create an IPLD DAG (Directed Acyclic Graph)
- the IPLD DAG is serialized to a CAR file and bit padded to make a Filecoin Piece
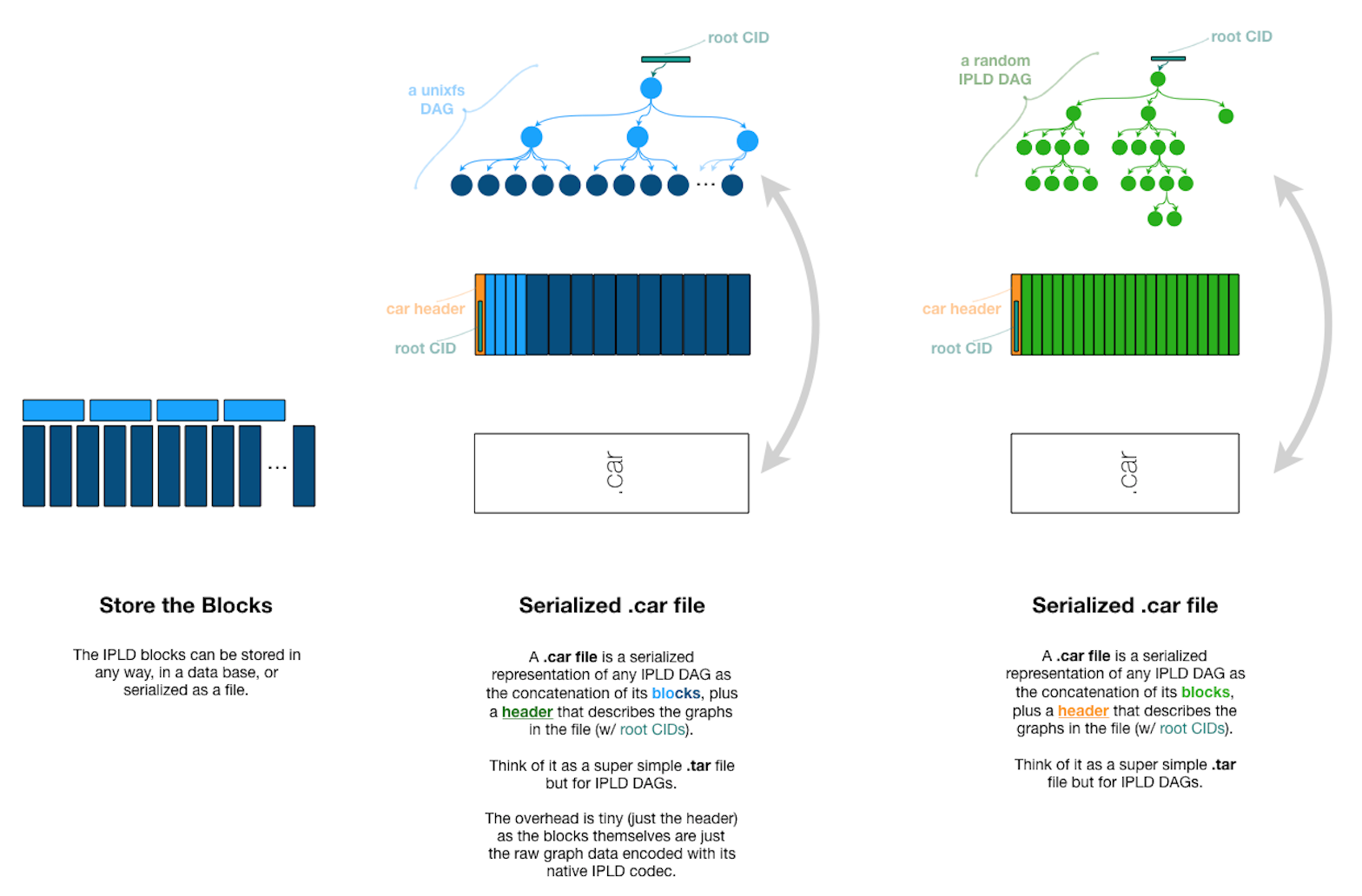
In the negotiation process for storage, a piece CID is wrapped with other deal parameters to create a Deal Proposal. The client sends this deal proposal to a miner, who agrees to store their data. Once the miner has confirmed, the client transfers their data to the miner. Once the miner has the data and verifies that it matches the piece CID noted in the deal proposal, they publish the deal proposal on Filecoin’s blockchain, committing both parties to the deal.
Proof of Replication (PoRep): a storage miner proves that they are storing a physically unique copy, or replica, of the data. Proof of Replication happens just once, at the time the data is first stored by the miner
Proof of Spacetime (PoSt): Proof of Spacetime (PoSt) will run repeatedly to prove that they are continuing to dedicate storage space to that same data over time
Reference
ProtoSchool: https://proto.school/
IPFS Docs: https://docs.ipfs.io/